Community Story: LahjaRAG Bridges the Gap Between Arabic Dialects

Team Yaa (ي) proudly secured 3rd place at the HALA!: Hackathon for Arabic Language in Abu Dhabi, hosted by aiXplain. The hackathon was kicked off at the Arabic NLP Winter School co-located with the 31st International Conference on Computational Linguistics (COLING 2025). Our solution, LahjaRAG, is a contextual, retrieval-augmented Arabic dialect-to-dialect translation system that bridges the linguistic gaps across regional dialects through intelligent prompt augmentation and language model generation.
Problem: Communication Barriers Across Arabic Dialects
Arabic is a rich and diverse language, but its dialectal variation across regions poses a major challenge in everyday communication. While machine translation has seen tremendous strides, Arabic dialect-to-dialect translation remains a largely uncharted frontier.
Key challenges in Arabic dialect translation
- Dialectal fragmentation: Arabic dialects differ significantly in vocabulary, syntax, and pronunciation, even among neighboring regions.
- Lack of research: Most NLP systems focus on dialect-to-MSA or dialect-to-English translations, leaving dialect-to-dialect translation overlooked.
- Insufficient resources: Standardized datasets for dialect translation are scarce, especially for underrepresented dialects.
- Code-switching complexity: Real-world conversations often mix dialects, further complicating the task for standard LLMs.
Why this matters
This fragmentation limits effective cross-regional collaboration, hampers media localization, and weakens customer interaction for businesses targeting the Arabic-speaking world.
Goal: Enabling Seamless Dialectal Communication
Our goal was to build an intelligent agent capable of translating between six major Arabic dialects—MSA, Tunisian, Egyptian, Moroccan, Lebanese, and Qatari—while exceeding the limitations of conventional LLMs. We aimed to harness the power of retrieval-augmented generation (RAG) to ensure high-fidelity, context-sensitive translations enriched with region-specific expressions and verb structures.
Key Features
- Dialect-to-dialect translation: Accurate, user-friendly translations across six Arabic dialects.
- Retrieval-enhanced prompts: Contextual examples fetched via BM25 augment the LLM prompt to improve translation fidelity.
- Improved verb and phrase coverage: Superior handling of dialect-specific linguistic features, especially in verb usage.
- Human-centric evaluation: Beyond BLEU scores, we emphasize human interpretability and usability.
Technology Overview
Tech stack
- Languages: Python
- Frameworks: Hugging Face Transformers, scikit-learn, pandas
- Tools: Pyserini (BM25), TF-IDF, cosine similarity, aiXplain API
- LLMs: GPT-based and Qwen-based language models
Methodology
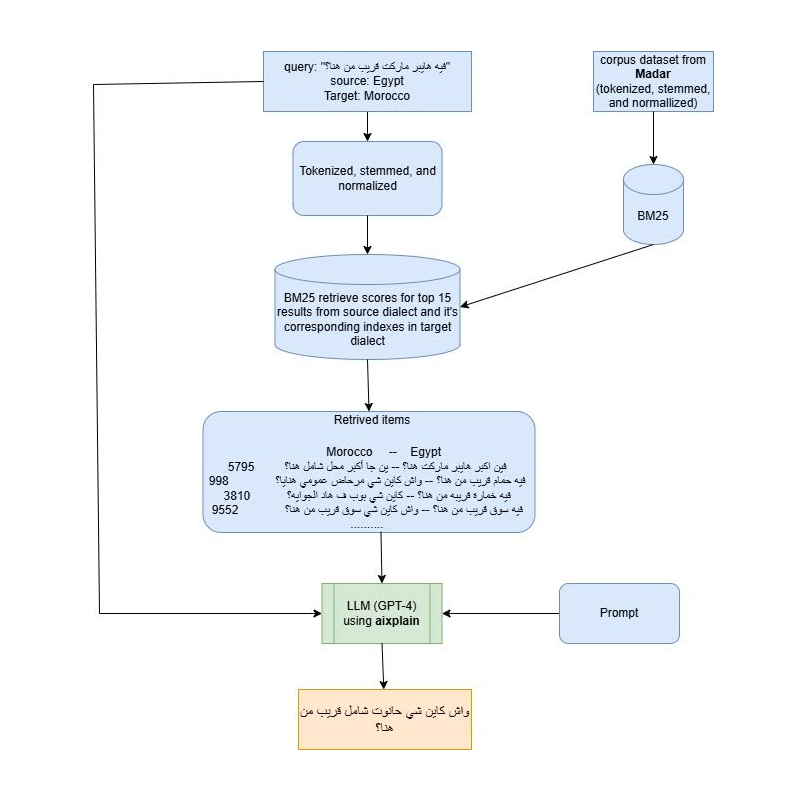
To deliver superior dialectal translations, we built a RAG pipeline that intelligently combines the power of lightweight textual retrieval models like TF-IDF/BM25 with large language models (LLMs) for rich, dialect-aware translation output. This design enables our system to retrieve contextually similar examples from a curated parallel dataset and use them to guide the generation of translations more accurately than one-shot prompting alone.
Step 1: Curating the dataset from the MADAR Corpus
The first step was building a clean and representative dataset using the MADAR Parallel Corpus, which contains aligned sentence pairs across multiple Arabic dialects.
We filtered and merged the most relevant splits: corpus-6-train and corpus-6-test-corpus-26-train. This ensures that our retrieval engine has access to real-world dialect examples with consistent alignment.
import pandas as pd
# Load and filter data from MADAR Corpus
def load_and_combine_splits(filepath):
df = pd.read_csv(filepath, sep="\t")
return df[df['split'].isin(['corpus-6-train', 'corpus-6-test-corpus-26-train'])]
# Combine all dialects into a single dataframe
files = {
"Cairo": "MADAR.corpus.Cairo.tsv",
"MSA": "MADAR.corpus.MSA.tsv",
"Beirut": "MADAR.corpus.Beirut.tsv",
"Doha": "MADAR.corpus.Doha.tsv",
"Rabat": "MADAR.corpus.Rabat.tsv",
"Tunis": "MADAR.corpus.Tunis.tsv"
}
final_combined_data = pd.DataFrame()
for dialect, path in files.items():
splits = load_and_combine_splits(path)
splits["Dialect"] = dialect
final_combined_data = pd.concat([final_combined_data, splits], ignore_index=True)
final_combined_data.to_csv("final_combined_train_data.tsv", sep="\t", index=False)Step 2: Implementing contextual retrieval (TF-IDF / BM25)
Once the dataset was curated, we focused on retrieving the most relevant parallel examples using TF-IDF with cosine similarity (or optionally BM25). These examples form the “context block” in a few-shot prompt to guide the LLM toward a more dialect-aware translation.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise
import cosine_similarity
# Load preprocessed MADAR data
madar_data = pd.read_csv("restructured_combined_train_data.tsv", sep="\t")
# Retrieve top-k similar examples
def retrieve_top_k_sentences(query, source_dialect, target_dialect, k=5):
vectorizer = TfidfVectorizer()
source = madar_data[source_dialect].fillna("")
target = madar_data[target_dialect].fillna("")
tfidf_matrix = vectorizer.fit_transform(source)
query_vec = vectorizer.transform([query])
similarity = cosine_similarity(query_vec, tfidf_matrix).flatten()
top_k_indices = similarity.argsort()[-k:][::-1]
return source.iloc[top_k_indices].tolist(), target.iloc[top_k_indices].tolist()Step 3: Constructing a few-shot prompt and LLM translation via aiXplain API
Once the top-k source/target examples are retrieved, we craft a dynamic few-shot prompt that guides the LLM with real parallel dialect samples and finally, the prompt is submitted to the aiXplain GPT model using their SDK:
PROMPT_TEMPLATE = """Translate the sentence from {source_dialect} to {target_dialect} based on the context.
Context (examples):
{context}
Query:
{query}
Translation:"""
def generate_prompt(query, top_k_source, top_k_target, source_dialect, target_dialect):
examples = "\n".join([f"{src} -> {tgt}" for src, tgt in zip(top_k_source, top_k_target)])
return PROMPT_TEMPLATE.format(
source_dialect=source_dialect,
target_dialect=target_dialect,
context=examples,
query=query
)
from aixplain.factories import ModelFactory
model_id = "6646261c6eb563165658bbb1" # Custom dialectal model
model = ModelFactory.get(model_id)
response = model.run(prompt)
print("Generated Translation:")
print(response.data)Results
Our RAG pipeline demonstrated clear improvements in producing natural and contextually accurate dialect translations, especially for idiomatic verbs and local expressions. When compared to standard MADAR outputs or baseline LLMs, LahjaRAG translations aligned more closely with human interpretation, even if BLEU scores remained low.
Output example
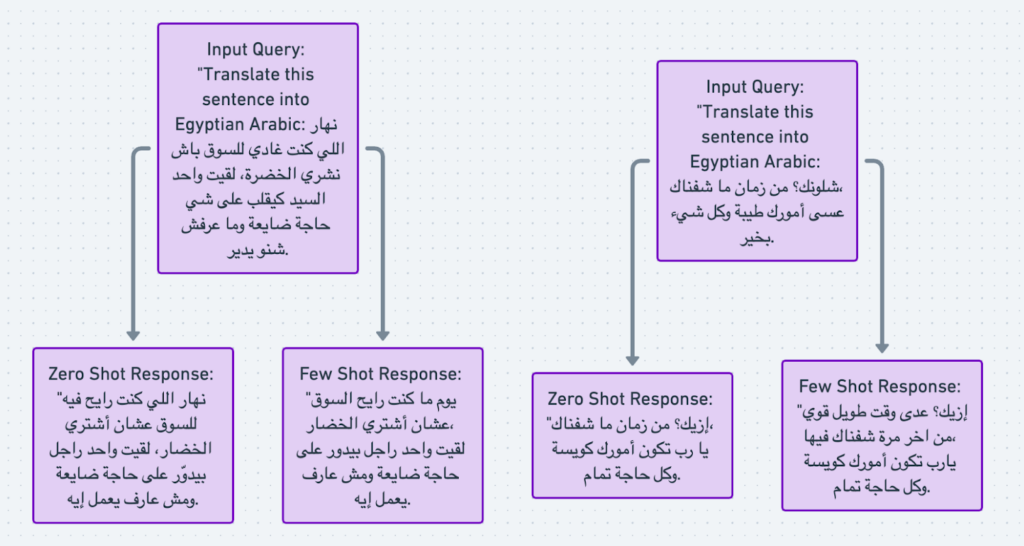
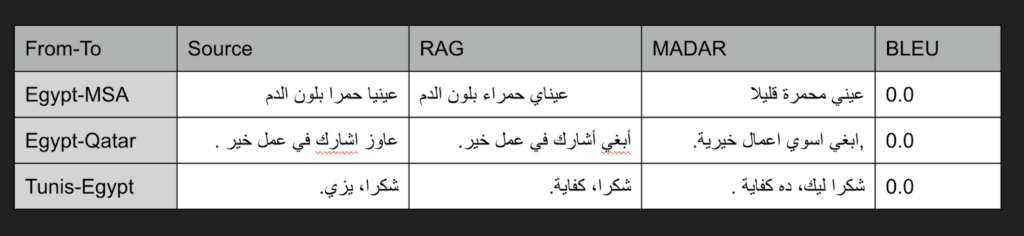
Performance metrics
While BLEU score is a widely adopted metric in machine translation, it falls short in evaluating dialectal translations for the following reasons:
- Surface-level matching: BLEU measures exact n-gram overlap, ignoring semantic equivalence.
- Low BLEU ≠ low quality: As seen in our results, human evaluators preferred the RAG outputs even when BLEU scores were 0.0.
For a more accurate assessment, semantic similarity metrics (e.g., BERTScore) or LLM-as-a-judge evaluations are better suited.
Despite the nearly identical meaning between our LahjaRAG and the MADAR ground truth corpus, BLEU failed to recognize acceptable alternative expressions due to dialectal flexibility and idiomatic translation variance.
Conclusion
LahjaRAG began with a bold question: Can we build machines that speak like us, not just in words but in dialects? Through our RAG pipeline, we demonstrated that it’s not only possible but practical. We tackled the complexity of dialect variation with retrieval-based contextual enrichment, a strategy that LLMs alone often lack.
Along the way, we faced challenges like BLEU score limitations and prompt design trade-offs but we also learned how much richer NLP systems can be with retrieval as their compass.
Future Work
Looking ahead, several improvements can enhance LahjaRAG’s capabilities:
- Enhanced evaluation metrics: Incorporate semantic similarity and human ranking evaluations.
- Low-resource dialect expansion: Expand LahjaRAG to include Gulf, Iraqi, and Yemeni dialects.
- User-centric applications: Build chatbot agents for customer service, media translation, and education.
- Model fine-tuning: Train custom small-scale dialectal LLMs with RAG integration for faster deployment.
 We have cookies!
We have cookies!