Math-Solving Agent: aiXplain vs. CrewAI vs. AutoGen
Why systematic tool use matters
Why Math Problems?
Math reasoning tasks capture one of the hardest challenges in AI: structured problem-solving. Unlike open-ended tasks, math problems come with a single, objective answer. Either the agent solves it correctly or it doesn’t. There is no ambiguity, no subjective evaluation. This makes math an ideal setting for testing advanced AI frameworks like agents.
Also, solving math problems typically requires more than just predicting the next token—it demands planning, step-by-step reasoning, and often the ability to execute precise calculations. These characteristics mirror the motivations behind the growing popularity of agent frameworks. If these frameworks promise better orchestration and tool use, then math is a fair and revealing test [1][2].
Challenge: Tool Use
On paper, using a single tool sounds easy. In practice, this is where most frameworks break down. Tool use has three stages, and failure at any stage leads to wrong answers [3][4]:
- First, the agent must decide when to use the tool versus relying on the language model alone. A misjudgment here can mean skipping the tool entirely, which is common in conversational frameworks.
- Second, if the tool is selected, the agent must execute it correctly by formatting the input exactly as required. Any syntactic mistake or missing parameter causes execution failures.
- Finally, after the tool produces a result, the agent needs to use that result faithfully. Ignoring the output or hallucinating a different number is a surprisingly frequent problem.
Experimental Setup
We created a level playing field to focus on orchestration logic, how well each framework coordinates reasoning and tool use, rather than relying on model size or tool complexity.
Frameworks
We compared three agent SDKs for building math solvers: aiXplain [5], CrewAI [6], and AutoGen [7].
Tool use
To isolate the agent’s tool-handling ability, we gave each framework access to just one utility: a Python code execution tool capable of basic arithmetic and statistical calculations. No complex APIs, no multiple tools. This setup forced each framework to:
- Decide when to use the tool vs. the LLM
- Format input correctly
- Integrate the output reliably and accurately
LLM
All agents used GPT-4o mini [8], a lightweight yet capable model. This allowed us to test how much an agentic workflow can boost performance on complex tasks without relying on massive model capacity. To remove prompt engineering as a variable, we used an identical prompt template across all frameworks.
Datasets
We selected two math benchmarks:
- GSM8K, a set of grade-school word problems requiring step-by-step reasoning [9]
- MMAU Math, a more challenging benchmark that includes diverse problem types and statistical reasoning [10]
Evaluation
We focused on three core metrics:
- Accuracy (correct answer rate)
- Latency (average time per query)
- Cost (USD per 100 problems)
These criteria reflect the practical trade-offs developers face when building scalable agent-based systems.
Solving Performance
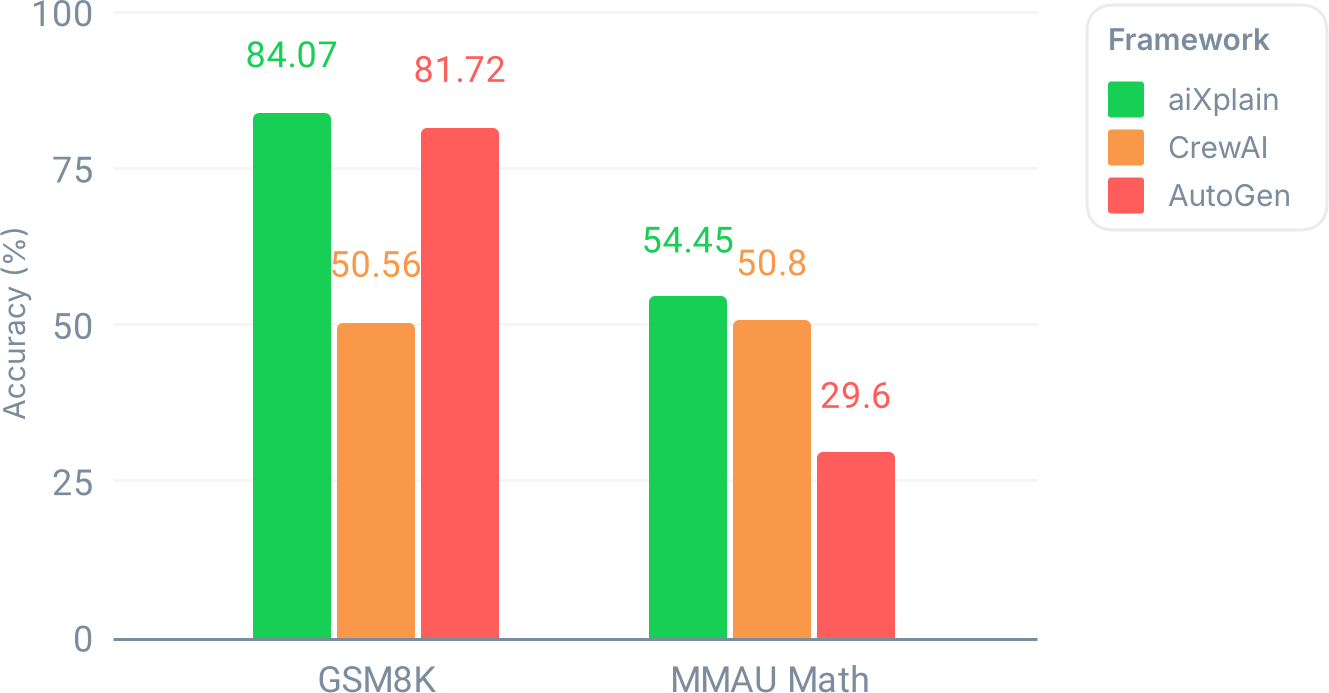
On GSM8K, aiXplain achieved an impressive 84.07% accuracy, outperforming both CrewAI (50.56%) and AutoGen (81.72%). On MMAU Math, which is significantly harder, aiXplain still led with 54.45%, while CrewAI scored 50.80% and AutoGen dropped sharply to 29.60%.
These numbers tell a clear story. aiXplain is consistently strong across both datasets. CrewAI, while far behind aiXplain on GSM8K, manages a somewhat competitive performance on MMAU. AutoGen, on the other hand, shows a dramatic drop when the problems get harder, suggesting weaknesses in its handling of tool outputs under more complex reasoning scenarios.
Tool Use Process Should Be Systematic
The secret lies in aiXplain’s disciplined orchestration strategy. It enforces a strict separation of tasks: tool selection, input preparation, and tool execution happen as distinct steps. This minimizes the chances of malformed calls or skipped actions. aiXplain also forces the integration of tool outputs into the reasoning chain. In other words, if the tool computes something, that number will be used—not ignored or hallucinated over. Finally, aiXplain automatically reformats tool outputs when needed, preventing downstream failures and improving robustness. This approach may introduce overhead, but the payoff is clear: higher accuracy across diverse problem types.
CrewAI’s primary weakness lies in the quality of the code it generates during tool use. The tool calls frequently suffer from issues such as missing imports or syntax errors, suggesting that the framework does not consistently provide well-structured context for code generation. When execution fails, the agent often retries the same tool call without meaningful correction or falls back to guessing the answer, leading to both inefficiency and reduced accuracy.
AutoGen often defaulted to pure LLM reasoning, bypassing the tool altogether. Even when the tool was used, the framework frequently failed to incorporate its output reliably into the final answer. While AutoGen includes a self-reflection mechanism intended to promote better tool use, in practice it was ineffective at enforcing tool invocation or ensuring proper utilization of the tool results.
Here is an example of how each framework approached the classic “Lemon Tree Problem” in GSM8K, which asks when an investment becomes profitable.
Question: Carlos plants a lemon tree. Cost: $90. Annual income: 7 lemons × $1.5. Annual maintenance: $3/year.
Correct answer: 13 years to break even.# aiXplain
# Answer: 13
initial_cost = 90
lemons_per_year = 7
price_per_lemon = 1.5
annual_cost = 3
years = 0
total_cost = initial_cost
while True:
income = lemons_per_year * price_per_lemon
total_cost += annual_cost
if income * years > total_cost:
break
years += 1
years# CrewAI
# Answer: 14
initial_cost = 90
net_income_per_year = (7 * 1.5) - 3
years = 0
while initial_cost > 0:
initial_cost -= net_income_per_year
years += 1
print(years)# AutoGen
# Answer: 12
initial_cost = 90
lemon_growth_per_year = 7
lemon_price = 1.5
annual_cost = 3
years = 0
net_profit = -initial_cost
while net_profit < 0:
years += 1
net_profit += (lemon_growth_per_year * lemon_price) - annual_cost
yearsCrewAI’s agent produced a solution that overshot the correct break-even year. It generated a loop-based code structure but failed to revisit or verify whether the stopping condition aligned with the problem’s requirements. Once the initial code was produced, no further reasoning was applied to refine or validate the logic, resulting in an answer that missed the mark.
AutoGen’s agent, on the other hand, stopped one year too early. It accepted the first tool output without checking whether the profit calculation accounted for all yearly expenses. Although a self-reflection mechanism was enabled, it failed to trigger a re-evaluation of the break-even condition, revealing a gap between tool use and logical validation.
aiXplain’s agent arrived at the correct answer by tightly aligning reasoning, code generation, and result interpretation. Its orchestration logic ensured that the tool was invoked at the right moment, with a code structure that faithfully represented the break-even logic. The output required no post-hoc corrections or manual patches, and everything worked as intended from end to end.
This example illustrates the critical role of reasoning quality and orchestration discipline in agent performance, even when using the same tool and model.
Efficiency Metrics
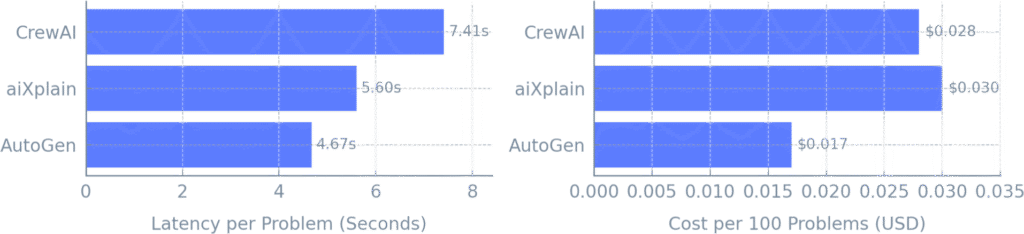
Latency and cost data add further nuance to the comparison. AutoGen emerged as the fastest and most cost-efficient overall, despite its poor performance on MMAU. Its minimal tool-handling logic likely helped reduce overhead, but at the cost of accuracy. aiXplain, while not the fastest, delivered strong average latency and came second in overall cost, which is notable given its top-tier accuracy. The extra computation likely stems from its structured execution process, including enforced tool use and output reformatting, especially on harder problems. CrewAI showed the slowest average latency but had the lowest cost, suggesting that although it spends more time per problem, it may be more frugal in its API usage or retries fewer steps, possibly due to weaker orchestration logic.
Conclusion
This experiment reinforced a key insight: better orchestration matters more than architectural complexity. Sophisticated layers or dynamic behaviors are not enough; what drives strong performance is disciplined tool use and structured workflows. Among the three frameworks tested, aiXplain consistently stood out for aligning reasoning, tool execution, and result integration. That said, its accuracy advantage comes at a cost, though the difference is not significant.
Math problems are just the beginning. Next steps include integrating symbolic tools like SymPy and WolframAlpha, and expanding to code-intensive domains, where orchestration challenges become even more pronounced. We’re also exploring self-verification loops that can dynamically balance cost and accuracy during execution.
Try it Yourself
All aiXplain experiments were powered by its aiXplain SDK. You can find the detailed recipe here.
References
[1] Xie et al., MathLearner: A Large Language Model Agent Framework for Learning to Solve Mathematical Problems, arxiv:2408.01779
[2] Glazer et al., FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI, arxiv:2411.04872
[3] Cemri et al., Why Do Multi-Agent LLM Systems Fail?, arxiv:2503.13657
[4] Niklas Heidloff, Why Agents and Agentic Systems Can Fail
[5] Sharma et al., aiXplain SDK: A High-Level and Standardized Toolkit for AI Assets, INLG 2024
[6] CrewAI, Inc., CrewAI
[7] Wu et al., AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversations, COLM 2024
[8] OpenAI, GPT-4o mini: Advancing Cost-efficient Intelligence
[9] Cobbe et al., Training Verifiers to Solve Math Word Problems, arXiv:2110.14168
[10] Yin et al., MMAU: A Holistic Benchmark of Agent Capabilities Across Diverse Domains, NAACL 2025 Findings
 We have cookies!
We have cookies!